Web Scraping
Table of Contents
Scraping Instagram
Profile Data
This is a function to scrape the user data and the last 12 posts from that user. Set this up as a recurring cron job and it could scrape multiple users and store the data. R code is adapted from this post, which was written in python. We’re also using the rjsoncons package, which allows for JMESpath subsetting of JSON data. Since we’re adding headers to the GET request, we’ll use the httr package, rather than rvest.
library(httr)
library(jsonlite)
# function to parse data and put into list
parse_user <- function(data) {
# get data on the account
account_data <- rjsoncons::jmespath(data, "data.user.{
name: full_name,
username: username,
id: id,
category: category_name,
business_category: business_category_name,
phone: business_phone_number,
email: business_email,
bio: biography,
bio_links: bio_links[].url,
homepage: external_url,
followers: edge_followed_by.count,
follows: edge_follow.count,
facebook_id: fbid,
is_private: is_private,
is_verified: is_verified,
profile_image: profile_pic_url_hd,
video_count: edge_felix_video_timeline.count,
image_count: edge_owner_to_timeline_media.count,
saved_count: edge_saved_media.count,
related_profiles: edge_related_profiles.edges[].node.username
}"
) |>
fromJSON()
# get post data
post_data <- rjsoncons::jmespath(data, "data.user.edge_owner_to_timeline_media.edges[].node.{
post_date: taken_at_timestamp,
typename: __typename,
type: is_video,
id: id,
shortcode: shortcode,
thumbnail: thumbnail_src,
video_url: video_url,
caption: edge_media_to_caption.edges[].node.text,
video_viewcount: video_view_count,
comment_count: edge_media_to_comment.count,
like_count: edge_liked_by.count,
location: location.name,
music_artist: clips_music_attribution_info.artist_name,
song_name: clips_music_attribution_info.song_name
}"
) |>
fromJSON() |>
mutate(post_date = as.POSIXct(post_date, origin = "1970-01-01"))
list(account_data = account_data, post_data = post_data)
}
scrape_user <- function(username) {
INSTAGRAM_APP_ID <- "936619743392459" # this is the public app id for instagram.com
url <- paste0("https://i.instagram.com/api/v1/users/web_profile_info/?username=", username)
response <- GET(
url = url,
add_headers(`x-ig-app-id` = INSTAGRAM_APP_ID)
)
data <- content(response, "text")
parse_user(data)
}
out <- scrape_user('bmw')
Two lists are saved. The first is the account data.
out$account_data[c(1,2,3,5,8,11:12,17,18)] |>
cbind() |>
data.frame() |>
set_names(nm = "") |>
knitr::kable()
| name | BMW |
| username | bmw |
| id | 43109246 |
| business_category | Auto Dealers |
| bio | The official #BMW account, home of Sheer Driving Pleasure. |
| Use #BMWrepost for the chance to get featured. | |
| followers | 37361042 |
| follows | 76 |
| video_count | 49 |
| image_count | 10594 |
The second is the post data that we’ve pulled.
out$post_data |>
head(3) |>
knitr::kable()
| post_date | typename | type | id | shortcode | caption | video_viewcount | comment_count | like_count | location | music_artist | song_name |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023-09-05 09:12:49 | GraphVideo | TRUE | 3185240436572707198 | Cw0P00KIFl- | Taking over our hometown in our home colours 💙🤍 #NeueKlasse #IAA23 #THEVisionNeueKlasse #TheNeueNew | 678386 | 813 | 164169 | Max-Joseph-Platz | ottocarclub | Original audio |
| 2023-09-07 01:00:45 | GraphVideo | TRUE | 3186442829185025149 | Cw4hN7iqgR9 | Every decision is an act of creation, shaping the path of our journey. THE NEUE NEW. The BMW Vision Neue Klasse. #NeueKlasse #IAA23 #THEVisionNeueKlasse #TheNeueNew | 325513 | 256 | 40401 | NA | bmw | Original audio |
| 2023-09-08 10:34:30 | GraphVideo | TRUE | 3187455988330466509 | Cw8HlVhoQzN | BMW faces its toughest critic yet @liamcarps1 🫣 Shop Liam’s look via the link in bio. #NeueKlasse #IAA23 #THEVisionNeueKlasse #TheNeueNew #BMW | 1540983 | 959 | 121633 | NA | bmw | Original audio |
Scraping Post Data
We can also scrape post level data. The wrapper function is written in R, but a lot of the work is done via Python scripts. All that the user has to provide is the user_name and number of pages to return. Each page contains 12 posts.
scrape_instagram <- function(user_name, max_pages) {
pacman::p_load(tidyverse, janitor, here, glue, reticulate)
if (max_pages > 10) {
sleep_time <- 5L
} else {
sleep_time <- 2L
}
# LOAD FUNCTIONS ----------------------------------------------------------
# R FUNCTIONS
source("~/R/scrapper/instagram/R/ig_scrape_user.R") # scrapes the user
source("~/R/scrapper/instagram/R/ig_parse_user.R") # parsed the user data into a list
source("~/R/scrapper/instagram/R/ig_clean_posts.R")
# PYTHON FUNCTIONS
source_python("~/R/scrapper/instagram/python/ig_parse_post.py")
source_python("~/R/scrapper/instagram/python/ig_scrape_single_post.py")
source_python("~/R/scrapper/instagram/python/ig_scrape_user_posts_detail.py")
# 1. GET USER DATA --------------------------------------------------------
# this is necessary to get the user ID
user <- ig_scrape_user(user_name)
parsed_user <- ig_parse_user(user)
# 2. GET POST DATA --------------------------------------------------------
httpx <- import("httpx") # Create a Python session using httpx
session <- httpx$Client(timeout = httpx$Timeout(20.0)) # Create an HTTPX session object in Python
post_df <- ig_scrape_user_posts_detail(
user_id = parsed_user$account_data$id,
session = session,
page_size = 12L,
max_pages = max_pages, # Optional: Limit the number of pages to scrape
sleep_time = sleep_time
)
session$close()
# 3. CLEAN THE DATA AND RETURN -------------------------------------------
clean_posts <- ig_clean_posts(post_df)
return(clean_posts)
}
out <- scrape_instagram("bmw", max_pages = 2)
out[c(1:2, 15:16)]
## post_date url
## 1 2025-01-16 08:01:09 https://www.instagram.com/p/DE5HUT1oKn-
## 2 2025-01-16 05:01:14 https://www.instagram.com/p/DE4yuAJK_T2
## 15 2025-01-23 08:02:51 https://www.instagram.com/p/DFLItEVtT_Y
## 16 2025-01-23 07:20:07 https://www.instagram.com/p/DFLENULOfx1
## caption
## 1 We shine in the dark ✨\n\nThe BMW i7. 100% electric. \n#THEi7 #BMW #BMWElectric
## 2 What we mean when we say self-care 🧽\n\nThe BMW i7. 100% electric. \n#THEi7 #BMW #BMWElectric
## 15 Signed, sealed, delivered. \n\nThe BMW M5 with the @redbulldriftbrothers sideways at @bmwwelt.\n\nWatch the full reel on the channel now. \n\n#BMW #BMWM #BMWWELT #THEM5 #BMWIndividual\n\nThe BMW M5 Sedan: Mandatory information according to German law ’Pkw-EnVKV’ based on WLTP: energy consumption weighted combined: 26.8 kWh/100 km and 1.9 l/100 km; CO₂ emissions weighted combined: 43 g/km; CO2 classes: with discharged battery G; weighted combined B; Fuel consumption with depleted battery combined: 10.7 l/100km; electric range: 66 km\n\nPaint finish shown: BMW Individual special paint Speed Yellow solid. Check the link in bio for the BMW Individual Visualizer to see more BMW Individual colour options.
## 16 Being bold will never go old. \n\nShop the BMW M oversized brown t-shirts and Erlkönig gilet from @bmwlifestyle via the link in bio and in select dealerships.\n\n#THEM5 #BMWLifestyle #BMWM #BMW \n\nThe new BMW M5 Sedan: Mandatory information according to German law ’Pkw-EnVKV’ based on WLTP: energy consumption weighted combined: 26.8 kWh/100 km and 1.9 l/100 km; CO₂ emissions weighted combined: 43 g/km; CO2 classes: with discharged battery G; weighted combined B; Fuel consumption with depleted battery combined: 10.7 l/100km; electric range: 63 km
## views plays likes comments video_duration collaborators
## 1 473077 2131529 194182 1787 8.811
## 2 580173 2712296 60728 477 16.939
## 15 204202 1289461 75870 555 21.199 bmw, bmwm, redbulldriftbrothers
## 16 NaN NaN 153243 668 NaN
## hashtags
## 1 #THEi7, #BMW, #BMWElectric
## 2 #THEi7, #BMW, #BMWElectric
## 15 #BMW, #BMWM, #BMWWELT, #THEM5, #BMWIndividual
## 16 #THEM5, #BMWLifestyle, #BMWM, #BMW
## media_link
## 1 https://scontent-sjc3-1.cdninstagram.com/o1/v/t16/f2/m86/AQOg1Ky9xbfVECX3bvhFUtdBHKv7o9mX-1dgqCp4K31XZS7G5Xz4KJsC0qNnaLu3H1fTz7W2mpzOvtSV88_SZej34JjJ5E3IW7RstqM.mp4?stp=dst-mp4&efg=eyJxZV9ncm91cHMiOiJbXCJpZ193ZWJfZGVsaXZlcnlfdnRzX290ZlwiXSIsInZlbmNvZGVfdGFnIjoidnRzX3ZvZF91cmxnZW4uY2xpcHMuYzIuNzIwLmJhc2VsaW5lIn0&_nc_cat=110&vs=568456509361022_967454477&_nc_vs=HBksFQIYUmlnX3hwdl9yZWVsc19wZXJtYW5lbnRfc3JfcHJvZC9FQjQwNkNFMDczMTREOEE5QkVBNDQxMjgyQ0E1Rjk4MV92aWRlb19kYXNoaW5pdC5tcDQVAALIAQAVAhg6cGFzc3Rocm91Z2hfZXZlcnN0b3JlL0dHemVNeHhBcUxpMDVOa0VBSF8yTUNjanMxUWRicV9FQUFBRhUCAsgBACgAGAAbABUAACaKipbwtoSyPxUCKAJDMywXQCGZmZmZmZoYEmRhc2hfYmFzZWxpbmVfMV92MREAdf4HAA%3D%3D&ccb=9-4&oh=00_AYA-VCvkAD7yK3W9Oc5RImyqafn6Vu_kinT2rnsaBLVZyQ&oe=6798A66E&_nc_sid=d885a2
## 2 https://scontent-sjc3-1.cdninstagram.com/o1/v/t16/f2/m86/AQOmrQsFDZZcfiDCWNGWgZaxSumLzvmxoGqXk-14EXiOGUHo4THo8dic5zt_6uizcKkf-P6tLqEHT7Vis_SCnGhz8wrXy2jX_OZuh-Q.mp4?stp=dst-mp4&efg=eyJxZV9ncm91cHMiOiJbXCJpZ193ZWJfZGVsaXZlcnlfdnRzX290ZlwiXSIsInZlbmNvZGVfdGFnIjoidnRzX3ZvZF91cmxnZW4uY2xpcHMuYzIuNzIwLmJhc2VsaW5lIn0&_nc_cat=111&vs=925850083087482_1767228440&_nc_vs=HBksFQIYUmlnX3hwdl9yZWVsc19wZXJtYW5lbnRfc3JfcHJvZC9COTQ3NTkyNEMzNjk1QzQ2MTEzMDBBREM5NzA1QkQ5MV92aWRlb19kYXNoaW5pdC5tcDQVAALIAQAVAhg6cGFzc3Rocm91Z2hfZXZlcnN0b3JlL0dEcUZNaHgwdWVkMUdaa0JBT01vOGxWa3VtZ2xicV9FQUFBRhUCAsgBACgAGAAbABUAACaGh5nIpfuwQBUCKAJDMywXQDDu2RaHKwIYEmRhc2hfYmFzZWxpbmVfMV92MREAdf4HAA%3D%3D&ccb=9-4&oh=00_AYBd4DrNHTbUKoKDMh5ousP_wmiCa1Fv3V0XYhDWMZ3F-w&oe=67988DF3&_nc_sid=d885a2
## 15 https://scontent-sjc3-1.cdninstagram.com/o1/v/t16/f2/m86/AQNcBzoBGCcWdW4Wc8gXRLaSaFXTUgo_nUls-3F2a6H7e_KM6HVU5jFoFDIGJFMIqbOj4y--VeYlpVs3e_228p7ylmJtAHU4Z_X-KbQ.mp4?stp=dst-mp4&efg=eyJxZV9ncm91cHMiOiJbXCJpZ193ZWJfZGVsaXZlcnlfdnRzX290ZlwiXSIsInZlbmNvZGVfdGFnIjoidnRzX3ZvZF91cmxnZW4uY2xpcHMuYzIuNzIwLmJhc2VsaW5lIn0&_nc_cat=108&vs=2151982308533041_4058955520&_nc_vs=HBksFQIYUmlnX3hwdl9yZWVsc19wZXJtYW5lbnRfc3JfcHJvZC8wRTQ1QjBEOUE2RDFBNjI4MUUxMzhCQkY2Q0MzMDVCNl92aWRlb19kYXNoaW5pdC5tcDQVAALIAQAVAhg6cGFzc3Rocm91Z2hfZXZlcnN0b3JlL0dMVVhUeHp5V2YybHVTa0dBRnVEek42Z21sczVicV9FQUFBRhUCAsgBACgAGAAbABUAACa8s9DKqa6OQBUCKAJDMywXQDUwIMSbpeMYEmRhc2hfYmFzZWxpbmVfMV92MREAdf4HAA%3D%3D&ccb=9-4&oh=00_AYCcg77xLKB8JoLR3OdoZsTr5w3eBYiPGe34kctSvAn5Hw&oe=67989FE7&_nc_sid=d885a2
## 16 https://scontent-sjc3-1.cdninstagram.com/v/t51.2885-15/474754627_1126112715679825_3972589647703166490_n.jpg?stp=dst-jpg_e35_tt6&_nc_ht=scontent-sjc3-1.cdninstagram.com&_nc_cat=101&_nc_ohc=Xc5NHDoXH_EQ7kNvgEIXpvB&_nc_gid=58de59e0a6c44786a7c07aa205b8be98&edm=ANTKIIoBAAAA&ccb=7-5&oh=00_AYApN-DbGKz8LdRtp0MVAZzjJ0s9J91ScnAKNsqdPjDFJA&oe=679C90EF&_nc_sid=d885a2
## link_expiry
## 1 2025-01-28 01:42:06
## 2 2025-01-27 23:57:39
## 15 2025-01-28 01:14:15
## 16 2025-01-31 00:59:27
Scraping hidden data
In this example I show how when there is an identifiable script, that we can scrape the javascript from a dynamically loaded site. But what to do when this hidden data is loaded via a generic script? When this occurs, we have to do some parsing. It can be a pain, but being able to do this correctly opens a whole new world of data availability.
As an example, we’re going to use the Home Depot state by state store location page. In this case, for the state of Alabama. This data is actually easily scrapable using rvest and css selection, but pulling the JSON is far more convenient, and often yields additional information.
After loading the page, we go to devtools and search for part of the first address. As can be seen, the script isn’t identified, but we see the window.__APOLLO_STATE__:. We’re going to use this little bit to find the JSON data.
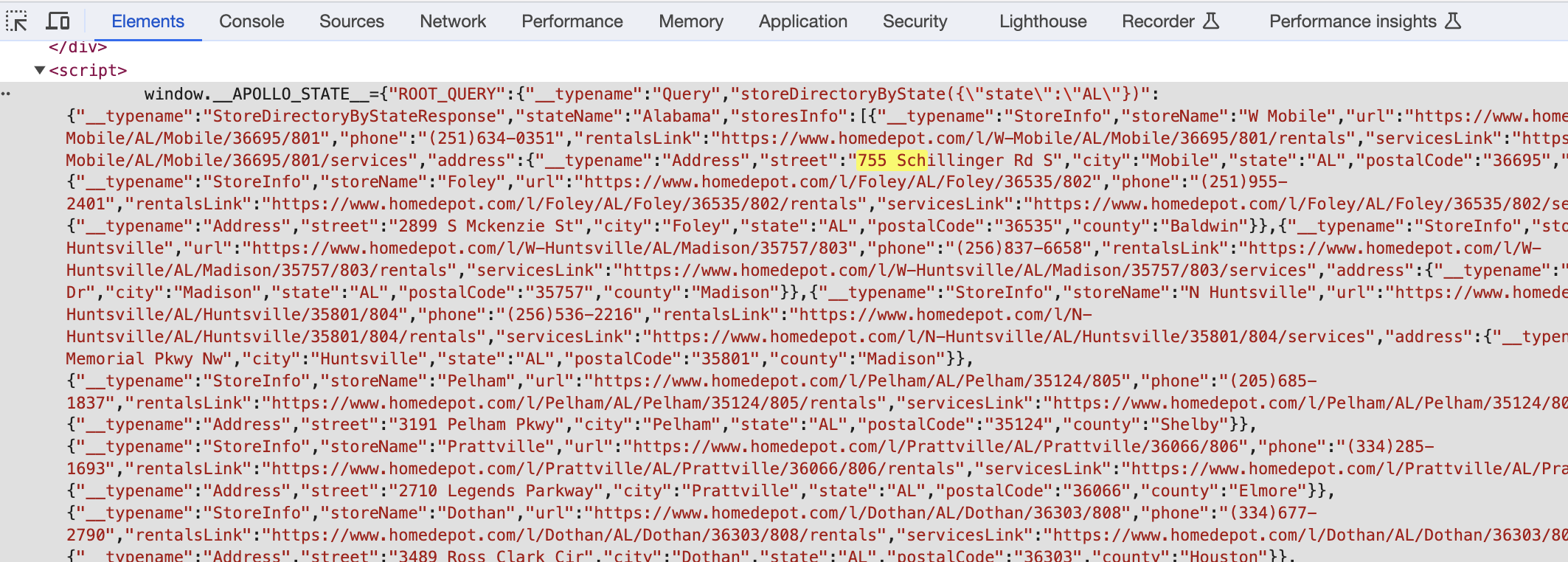
httr package to request the page and then parse it.
# Define the URL
url <- "https://www.homedepot.com/l/AL"
# Send a GET request to the URL
response <- GET(url)
# Check if the request was successful
(http_status(response)$category == "Success")
# Parse the HTML content from the response
html_content <- content(response, as = "text", encoding = "UTF-8")
Now that we have our content in text format, we have to find that script identifier. The start_pos variable is finding the location after the window.__APOLLO_STATE__= text is found. The end_pos_relative is looking for the location of the end of the JSON. In this case, becasue the data is nested, we’re looking for 3 end brackets. This will change depending on the structure of the data.
# Find the position of the substring "window.__APOLLO_STATE__="
start_pos <- str_locate(html_content, "window.__APOLLO_STATE__=")[2] + 1
# If the start position is found, proceed to find the end position and extract the JSON string
end_substring <- str_sub(html_content, start = start_pos)
end_pos_relative <- str_locate(end_substring, "\\}\\}\\}")
Now we adjust our end position relative to where our JSON data started, extract the data, and parse it with the jsonlite::fromJSON() function.
# Assuming we found the end_pos, adjust end_pos relative to start_pos
end_pos <- end_pos_relative[2] + start_pos - 1
# Extract the JSON string using substring
json_str <- substr(html_content, start_pos, end_pos)
# Parse the JSON string to a list
json_data <- fromJSON(json_str, flatten = TRUE)
Because our data is nested, it’s going to parse as a list. Calling the data, we can see that our data can be found in the following location.
stores_df <- json_data$ROOT_QUERY$`storeDirectoryByState({"state":"AL"})`$storesInfo |>
select(storeName, address.street, address.city, address.state,
address.postalCode, address.county, url, phone)
head(stores_df)
## storeName address.street address.city address.state address.postalCode address.county
## 1 W Mobile 755 Schillinger Rd S Mobile AL 36695 Mobile
## 2 Foley 2899 S Mckenzie St Foley AL 36535 Baldwin
## 3 W Huntsville 4045 Lawson Ridge Dr Madison AL 35757 Madison
## 4 N Huntsville 1035 Memorial Pkwy Nw Huntsville AL 35801 Madison
## 5 Pelham 3191 Pelham Pkwy Pelham AL 35124 Shelby
## 6 Prattville 2710 Legends Parkway Prattville AL 36066 Elmore
## url phone
## 1 https://www.homedepot.com/l/W-Mobile/AL/Mobile/36695/801 (251)634-0351
## 2 https://www.homedepot.com/l/Foley/AL/Foley/36535/802 (251)955-2401
## 3 https://www.homedepot.com/l/W-Huntsville/AL/Madison/35757/803 (256)837-6658
## 4 https://www.homedepot.com/l/N-Huntsville/AL/Huntsville/35801/804 (256)536-2216
## 5 https://www.homedepot.com/l/Pelham/AL/Pelham/35124/805 (205)685-1837
## 6 https://www.homedepot.com/l/Prattville/AL/Prattville/36066/806 (334)285-1693
Scraping YouTube
YouTube has an API, but it can be rate limited pretty quickly. The following will get performance metrics and all comments from each video, without running into any limit.
Set up
Within a conda environment created via the reticulate package, install yt-dlp (more detail).
reticulate::conda_install("[ENV Name]", "yt-dlp", pip = TRUE)
Next, write the python function that will call the yt-dlp library and pull the video metrics and comments for any url that’s passed to it.
def youtube_dl_info(URL):
import json
import yt_dlp
# See help(yt_dlp.YoutubeDL) for a list of available options and public functions
ydl_opts = {'getcomments':True}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(URL, download=False)
return(info)
After that, write quick function to clean the urls that we’re going to read in.
yt_clean <- function(file_loc) {
tmp <- readr::read_csv(file_loc) |>
dplyr::filter(stringr::str_detect(links, "^https://www.youtube.com/watch?")) |>
dplyr::distinct(links) |>
dplyr::pull()
}
Because I prefer to work in R, I need to get the data out of the python environment and into R. From there, I’m going to clean the data. The data will be split into two different dataframes - the summary metrics and the comments.
# to get data out of the returned lists #
youtube_extract <- function(datalist) {
# get summary data about the video
summary <- purrr::map_dfr(datalist,
magrittr::extract,
c("uploader", "upload_date", "title", "description", "categories",
"duration_string", "view_count",
"like_count", "comment_count", "original_url")) |>
dplyr::rename(duration = duration_string) |>
dplyr::mutate(upload_date = lubridate::ymd(upload_date))
# get the comments
x <- purrr::map(datalist, "comments")
# drop empty lists (no comments)
x <- Filter(length, x)
# loop over comments and put into dataframe
comments <- NULL
for (i in seq_len(nrow(summary))) {
print(i)
tmp <- x[[i]] %>%
data.table::rbindlist(fill = TRUE) |>
dplyr::as_tibble() |>
dplyr::mutate(timestamp = lubridate::as_datetime(as.numeric(timestamp, tz = "America/Los_Angeles"))) |>
dplyr::select(c(text, timestamp, like_count, author)) |>
dplyr::mutate(video = summary$title[i],
timestamp = as.Date(timestamp)) |>
dplyr::rename(date = timestamp)
comments <- rbind(comments, tmp)
tmp <- NULL
}
out <- list(summary = summary, comments = comments)
}
Finally, we write a wrapper function that will run the above functions and save the output into .rds and .xlsx files.
Everything in this function is referenced by the here() function. The directory structure looks like the following:
├── R
│ └── helpers
├── py_functions
├── youtube_report
│ └── youtube_data
├── yt_caption_data
└── yt_link_data
# YouTube metrics and comments #
# 1. start with LinkGopher to extract all urls
# 2. add links to a csv with the column name "links"
# 3. save csv as "[handle_name]_yt_links.csv" in the "yt_link_data" folder
# 4. run this function
yt_scrape_fn <- function(handle) {
# load packages
pacman::p_load(tidyverse, janitor, here, glue)
# load functions
reticulate::source_python(here::here('youtube', 'py_functions', 'youtube_dl_info.py'))
source(here('youtube','R','helpers', 'helpers.R'))
source(here('youtube','R', "youtube_extract.R"))
loc <- here('youtube','yt_link_data', glue("{handle}_yt_links.csv"))
urls <- yt_clean(loc)
# map over function and save to environment for safe processing
tmpdata <<- urls |>
purrr::map(youtube_dl_info)
# clean and add to reactive values
out <- youtube_extract(tmpdata)
outlist <- list(summary = out$summary, comments = out$comments)
saveRDS(outlist, here("youtube","youtube_report", "youtube_data", glue::glue("yt_{handle}_{Sys.Date()}.rds")))
openxlsx::write.xlsx(outlist, here("youtube","youtube_report", "youtube_data", glue::glue("yt_{handle}_{Sys.Date()}.xlsx")))
}
Getting the link data
We have to pass links into the function and to get them, we’re going to use the Link Gopher extension to pull all urls on the YouTube page of the account of interest. Then copy and paste the data and save as a csv.
Run it
As written, the script will save the data.
yt_scrape_fn("tesla")
And when the data is loaded, it looks like this
## # A tibble: 3 × 10
## uploader upload_date title description categories duration view_count like_count comment_count original_url
## <chr> <date> <chr> <chr> <chr> <chr> <int> <int> <int> <chr>
## 1 Tesla 2023-01-21 Tesla… "Tesla is … Autos & V… 2:17 619217 21844 1586 https://www…
## 2 Tesla 2023-03-31 Lars … "Engineere… Autos & V… 2:45 319640 15934 1089 https://www…
## 3 Tesla 2023-09-25 Tesla… "Optimus c… Autos & V… 1:18 28591 5882 729 https://www…
## # A tibble: 6 × 5
## # Groups: video [3]
## text date like_count author video
## <chr> <date> <int> <chr> <chr>
## 1 From Lars to Lars. Nice Explanation 👍 2023-09-24 NA @lars… Lars…
## 2 When you drill into the crash test data, it becomes apparent that the Mo… 2023-09-11 NA @cras… Lars…
## 3 And my car still can't drive itself halfway through the city in a light … 2023-09-25 NA @ne0n… Tesl…
## 4 The fact that it moves it whole body, hips included when moving the bloc… 2023-09-25 NA @Wify… Tesl…
## 5 I love to see them working very hard to replace every human on earth, ro… 2023-09-04 NA @Ahme… Tesl…
## 6 Please build artificial, noiseless, space- and energy-saving muscles int… 2023-08-25 NA @gk... Tesl…
Scraping TikTok
Code below can be used to scrape three different aspects of TikTok data - Profile data, Post data, Comments and comment data.
Profile data
The first thing we’ll scrape is the Profile data, which is found in a JavaScript script tag. The data is pretty comprehensive and is returned in a JSON format. A function to pull the data is below.
get_tt_user <- function(handle) {
pacman::p_load(tidyverse)
handle <- sub("^@", "", handle) # drop @ if it's there
link <- glue::glue("https://www.tiktok.com/@{handle}?lang=en")
# setting headers
headers = c(
`Accept` = '*/*',
`Accept-Language` = 'en-US,en;q=0.9',
`Connection` = 'keep-alive',
`Content-type` = 'application/x-www-form-urlencoded',
`DNT` = '1',
`Referer` = "https://www.google.com/",
`Sec-Fetch-Dest` = 'empty',
`Sec-Fetch-Mode` = 'cors',
`Sec-Fetch-Site` = 'same-origin',
`User-Agent` = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
`cache-control` = 'no-cache',
`pragma` = 'no-cache',
`sec-ch-ua` = '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
`sec-ch-ua-mobile` = '?0',
`sec-ch-ua-platform` = '"macOS"'
)
# GET request
res <- httr::GET(link, httr::add_headers(.headers = headers))
if (res$status_code != 200) {
stop(paste("Error: Received status code", res$status_code))
}
tmpout <- httr::content(res) |>
rvest::html_elements("script#__UNIVERSAL_DATA_FOR_REHYDRATION__") |>
rvest::html_text() |>
jsonlite::fromJSON()
out <- tmpout$`__DEFAULT_SCOPE__`$`webapp.user-detail`$userInfo
# build out a table of user data
tibble::tibble(name = out$user$nickname,
handle = out$user$uniqueId,
signature = out$user$signature,
verified = out$user$verified,
biolink = out$user$bioLink$link,
region = out$user$region,
followers = out$stats$followerCount,
following = out$stats$followingCount,
hearts = out$stats$heartCount,
videos = out$stats$videoCount,
diggs = out$stats$diggCount,
friends = out$stats$friendCount,
date_pulled = Sys.Date())
}
Let’s run it.
adre <- get_tt_user("addisonre")
adre |>
knitr::kable()
| name | handle | signature | verified | biolink | region | followers | following | hearts | videos | diggs | friends | date_pulled |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Addison Rae | addisonre | The world is my oyster 🧜🏼♀️ | TRUE | https://addisonrae.lnk.to/Aquamarine | US | 88600000 | 22 | 926500000 | 320 | 0 | 11 | 2025-01-26 |
Post data
Similar to profile data, post-level data can be found in a hidden script. The function to pull post level data is below.
get_tt_posts <- function(link){
# setting headers
headers = c(
`Accept` = '*/*',
`Accept-Language` = 'en-US,en;q=0.9',
`Connection` = 'keep-alive',
`Content-type` = 'application/x-www-form-urlencoded',
`DNT` = '1',
`Referer` = "https://www.google.com/",
`Sec-Fetch-Dest` = 'empty',
`Sec-Fetch-Mode` = 'cors',
`Sec-Fetch-Site` = 'same-origin',
`User-Agent` = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
`cache-control` = 'no-cache',
`pragma` = 'no-cache',
`sec-ch-ua` = '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
`sec-ch-ua-mobile` = '?0',
`sec-ch-ua-platform` = '"macOS"'
)
# GET request
res <- httr::GET(link, httr::add_headers(.headers = headers))
if (res$status_code != 200) {
stop(paste("Error: Received status code", res$status_code))
}
# content and pull script
tmpout <- httr::content(res) |>
rvest::html_elements("script#__UNIVERSAL_DATA_FOR_REHYDRATION__") |>
rvest::html_text() |>
jsonlite::fromJSON()
out <- tmpout$`__DEFAULT_SCOPE__`$`webapp.video-detail`$itemInfo$itemStruct
# build out a table of user data
tibble::tibble(id = out$id,
post_text = out$desc,
created_time = out$createTime,
duration = out$video$duration,
author_id = out$author$id,
author_uniqueID = out$author$uniqueId,
author_nickname = out$author$nickname,
author_signature = out$author$signature,
author_verified = out$author$verified,
like_count = out$stats$diggCount,
share_count = out$stats$shareCount,
comment_count = out$stats$commentCount,
play_count = out$stats$playCount,
collect_count = out$stats$collectCount,
diversification_labels = paste(out$diversificationLabels, collapse = ", "),
suggested_words = paste(out$suggestedWords, collapse = ", ")) |>
dplyr::mutate(hashtags = stringr::str_extract_all(post_text, "#\\S+"),
at_mentions = stringr::str_extract_all(post_text, "@\\S+"),
created_time = lubridate::as_datetime(as.integer(created_time), tz = "America/Los_Angeles"))
}
To run it, just provide a link
single_post <- get_tt_posts(link = "https://www.tiktok.com/@addisonre/video/7363016297233354027")
single_post |>
knitr::kable()
| id | post_text | created_time | duration | author_id | author_uniqueID | author_nickname | author_signature | author_verified | like_count | share_count | comment_count | play_count | collect_count | diversification_labels | suggested_words | hashtags | at_mentions |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7363016297233354027 | Got married at stagecoach. thank u @airbnb 🙏🏼 | 2024-04-28 13:24:14 | 30 | 6703550784929793030 | addisonre | Addison Rae | The world is my oyster 🧜🏼♀️ | TRUE | 485400 | 12300 | 1442 | 30100000 | 14988 | Romance, Relationship, Family & Relationship | Addison Rae, addison rae boyfriend, addison rae mom, addison rae scream, stagecoach, addison, addison rae and omer, Abby And Addison Rae, Stagecoach Outfits, josh richards addison rae | @airbnb |
Comment data (This is broken for the time being….)
Finally, we’ll pull the comments from a post. Comments aren’t found in a hidden script, but are loaded dynamically through hidden APIs as a user scrolls. We’re going to call the hidden API directly, and iterate through all of the comments to pull them. We can get 50 comments per API call, and one of the API parameters is cursor, which identifies where in the number of comments we want to start to pull our next 50.
There are several functions that will all be used in our convenience wrapper function. We’re going to use the same post as above.
parse_comments <- purrr::possibly(function(l){
# putting comment data into a cleaned tibble
tibble::tibble(
text = l$comments$text,
comment_language = l$comments$comment_language,
digg_count = l$comments$digg_count,
reply_comment_count = l$comments$reply_comment_total,
author_pin = l$comments$author_pin,
create_time = l$comments$create_time,
cid = l$comments$cid,
nickname = l$comments$user$nickname,
unique_id = l$comments$user$unique_id,
post_id = l$comments$aweme_id
) |>
dplyr::mutate(create_time = lubridate::as_datetime(create_time, tz = "America/Los_Angeles"))
}, otherwise = NA_character_)
scrape_comments <- function(post_id, cursor) {
# setting headers
headers = c(
`Accept` = '*/*',
`Accept-Language` = 'en-US,en;q=0.9',
`Connection` = 'keep-alive',
`Content-type` = 'application/x-www-form-urlencoded',
`DNT` = '1',
`Referer` = "https://www.google.com/",
`Sec-Fetch-Dest` = 'empty',
`Sec-Fetch-Mode` = 'cors',
`Sec-Fetch-Site` = 'same-origin',
`User-Agent` = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
`cache-control` = 'no-cache',
`pragma` = 'no-cache',
`sec-ch-ua` = '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
`sec-ch-ua-mobile` = '?0',
`sec-ch-ua-platform` = '"macOS"'
)
# build url and first pull
base_url <- "https://www.tiktok.com/api/comment/list/?"
params <- list(
aweme_id = post_id,
count = 50,
cursor = cursor
)
# GET request
res <- httr::GET(base_url, query = params, httr::add_headers(.headers = headers))
# parse data depending on cursor location
if (cursor == 0) {
tmp <- httr::content(res, "text") |>
jsonlite::fromJSON()
out <- list(comment_data = parse_comments(tmp), total_comments = tmp$total)
} else {
tmp <- httr::content(res, "text") |>
jsonlite::fromJSON()
out <- parse_comments(tmp)
}
}
fetch_tt_comments <- function(post_id) {
tmp <- scrape_comments(post_id, cursor = 0)
# get cursor starting locations
cursors <- (1:floor(tmp$total_comments/50)*50)+1
# map across cursor starts
out <- purrr::map2(post_id, cursors, scrape_comments)
out <- out[!is.na(out)]
out <- dplyr::bind_rows(out)
# bind all pulls together
rbind(tmp$comment_data, out)
}
We’ll run it and provide the first 5 comments.
fetch_tt_comments("7363016297233354027") |>
head(5) |>
knitr::kable()